零碎知识
柯理化
概念
柯里化(Currying)是一种处理函数中含有多个参数的方法,并在只允许单一参数的框架中使用这些函数。这种转变是现在被称为 “柯里化” 的过程,在这个过程中我们能把一个带有多个参数的函数转换成一系列的嵌套函数。它返回一个新函数,这个新函数期望传入下一个参数。当接收足够的参数后,会自动执行原函数。
柯里化的实现
现在我们已经知道了,当柯里化后的函数接收到足够的参数后,就会开始执行原函数。而如果接收到的参数不足的话,就会返回一个新的函数,用来接收余下的参数。基于上述的特点,我们就可以自己实现一个 curry 函数:
function curry(func) {
return function curried(...args) {
if (args.length >= func.length) { // 通过函数的length属性,来获取函数的形参个数
return func.apply(this, args);
} else {
return function (...args2) {
return curried.apply(this, args.concat(args2));
};
}
}
}
偏函数
概念
在计算机科学中,偏函数应用(Partial Application)是指固定一个函数的某些参数,然后产生另一个更小元的函数。而所谓的元是指函数参数的个数,比如含有一个参数的函数被称为一元函数。
偏函数的实现
偏函数用于固定一个函数的一个或多个参数,并返回一个可以接收剩余参数的函数。基于上述的特点,我们就可以自己实现一个 partial 函数:
function partial(fn) {
let args = [].slice.call(arguments, 1); //参数是从第二个参数开始传,第一个参数是传我要执行的函数
return function () {
const newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
}
与偏函数的区别
偏函数应用(Partial Application)很容易与函数柯里化混淆,它们之间的区别是:
- 偏函数应用是固定一个函数的一个或多个参数,并返回一个可以接收剩余参数的函数;
- 柯里化是将函数转化为多个嵌套的一元函数,也就是每个函数只接收一个参数。
数组扁平化
const arr = [1,[2],3,[[4],5]]
方法一(arr.flat)
arr.flat() //[1, 2, 3, Array(1), 5]
优点:方便,是数组自带的方法
缺点:对于层级层叠的数组没有办法
方法二(正则)
JSON.stringify(arr).replace(/\[|\]/g,'').split(',') //["1", "2", "3", "4", "5"]
优点:准确转化扁平化
缺点:麻烦,并且数组变成了字符串数组
方法三(正则究极版)
JSON.parse('['+JSON.stringify(arr).replace(/\[|\]/g,'').split(',')+']') //[1, 2, 3, 4, 5]
方法四(reduce)
const flatten = (arr) => {
return arr.reduce((pre,cur) => { //利用reduce递归最外层数组的每一个元素
return pre.concat(Array.isArray(cur) ? flatten(cur) : cur);//判断是否有层叠数组的情况,有的话进行flatten递归
})
}
flatten(arr) //[1, 2, 3, 4, 5]
数组去重(新)
const arr1 = [1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,3,3,3,3,3]
方法一(Set)
let set = new Set(arr1) //Set(3) {1, 2, 3}Array.from(set) //[1, 2, 3] //Set对象转换成数组
方法二(map)
const map = arr1=>{ //哈希表 const map = new Map(); const res = []; for(let i = 0 ;i < arr1,length; i++){ if(!map.has(arr[i])){ map.set(arr[i],true) res.push(arr[i]); } } return res;}
Object.assign
Object.assign方法用于对象的合并,将原对象的所有可枚举属性,复制到目标对象中
const source0 = { a: 1 };const source1 = { b: 2 };const source2 = { c: 3 };const target = {};Object.assign(target, source0, source1, source2) //{a: 1, b: 2, c: 3}
Object.assign方法的第一个参数是目标对象,后面的参数都是源对象。
注意,如果目标对象与源对象有同名属性,或多个源对象有同名属性,则后面的属性会覆盖前面的属性。
const target = { a: 1, b: 1 };const source1 = { b: 2, c: 2 };const source2 = { c: 3 };Object.assign(target, source1, source2);target // {a:1, b:2, c:3}
Object.keys
Object.keys()方法,返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键名。
let obj = { foo : "bar", baz : 18,}console.log(Object.keys(obj)); //["foo" , "baz"]
Array.some
some() 方法用于检测数组中的元素是否满足指定条件(函数提供)。
some() 方法会依次执行数组的每个元素:
- 如果有一个元素满足条件,则表达式返回true , 剩余的元素不会再执行检测。
- 如果没有满足条件的元素,则返回false。
注意: some() 不会对空数组进行检测。
注意: some() 不会改变原始数组。
a.some((i,index,array)=>{ console.log(i); return i>10})//11 true
[].map()
arr.map(fn(item,index,array))—>map能够接受传入一个回调函数fn,fn允许传入三个参数
分别为:
- item(数组当前的那一项)
- index (数组当前遍历这一项的 下标 或者说 索引 )
- arr(遍历回调函数所调用的数组)
遍历arr中的每一个元素去执行这一个回调函数
有趣的题
let arr = [27.2,0,'0013','14px',123];arr = arr.map(parseInt);console.log(arr);
因为parseInt的语法是——>parseInt([string],[radix]可选),需要传入两个参数,而这两个参数就对应这map回调函数中的前两位,所以arr.map(parseInt)可以看成arr.map(fn(item,index))
所以!!!
//这里的map函数中的结构为item index27.2 00 1'0013' 2'14px' 3123 4由于radix中只接受2-16进制,因此进制为1的直接转化为NaN,进制运算举例:parseInt('14px',3),首先取出14,然后计算3进制,由于1和4中,4不满足3进制,因此只有1,所以得出1*3^0因此结果为[27, NaN, 1, 1, 27]
轮询

Vue的data为什么是一个函数而不是一个对象?
JavaScript中的对象是引用类型的数据,当多个实例引用同一个对象时,只要一个实例对这个对象进行操作,其他实例中的数据也会发生变化。
而在Vue中,我们更多的是想要复用组件,那就需要每个组件都有自己的数据,这样组件之间才不会相互干扰。
所以组件的数据不能写成对象的形式,而是要写成函数的形式。数据以函数返回值的形式定义,这样当我们每次复用组件的时候,就会返回一个新的data,也就是说每个组件都有自己的私有数据空间,它们各自维护自己的数据,不会干扰其他组件的正常运行。
Prototype和_proto_


JS的事件机制(DOM0~DOM3)
DOM有4次版本更新,与DOM版本变更,产生了3种不同的DOM事件:DOM 0级事件处理,DOM 2级事件处理和DOM 3级事件处理。由于DOM 1级中没有事件的相关内容,所以没有DOM 1级事件。
DOM0
1.
- on-event(HTML属性)
<input onclick="alert('xxx')"/>
- on-event (非HTML 属性):
像是window或document此类没有实体元素的情况:
window.onload = function(){ document.write("Hello world!");};
若是实体元素:
// HTML<button id="btn">Click</button>// JavaScriptvar btn = document.getElementById('btn'); btn.onclick = function(){ alert('xxx'); }
若想解除事件的话,则重新指定on-event为null即可:
btn.onclick = null
同一个元素的同一种事件只能绑定一个函数(比如:onload只能绑一个触发函数),否则后面的函数会覆盖之前的函数
不存在兼容性问题
DOM2
- Dom 2级事件是通过 addEventListener 绑定的事件
- 同一个元素的同种事件可以绑定多个函数,按照绑定顺序执行
- 解绑Dom 2级事件时,使用 removeEventListener移除
btn.removeEventListener( "click" ,a)
Dom 2级事件有三个参数:第一个参数是事件名(如click);第二个参数是事件处理程序函数;
第三个参数如果是true的话表示在捕获阶段调用,为false的话表示在冒泡阶段调用。
还有注意removeEventListener():不能移除匿名添加的函数。
DOM3
DOM3级事件在DOM2级事件的基础上添加了更多的事件类型,增加的类型如下:
- UI事件,当用户与页面上的元素交互时触发,如:load、scroll
- 焦点事件,当元素获得或失去焦点时触发,如:blur、focus
- 鼠标事件,当用户通过鼠标在页面执行操作时触发如:dblclick、mouseup
- 滚轮事件,当使用鼠标滚轮或类似设备时触发,如:mousewheel
- 文本事件,当在文档中输入文本时触发,如:textInput
- 键盘事件,当用户通过键盘在页面上执行操作时触发,如:keydown、keypress
- 合成事件,当为IME(输入法编辑器)输入字符时触发,如:compositionstart
- 变动事件,当底层DOM结构发生变化时触发,如:DOMsubtreeModified
- 同时DOM3级事件也允许使用者自定义一些事件。
事件流(类洋葱模型,V字模型)
事件流(Event Flow)指的就是「网页元素接收事件的顺序」。事件流可以分成两种机制:
- 事件捕获(Event Capturing)
- 事件冒泡(Event Bubbling)
当一个事件发生后,会在子元素和父元素之间传播(propagation)。这种传播分成三个阶段:
- 捕获阶段:事件从window对象自上而下向目标节点传播的阶段;
- 目标阶段:真正的目标节点正在处理事件的阶段;
- 冒泡阶段:事件从目标节点自下而上向window对象传播的阶段。
接着就来分别介绍事件捕获和事件冒泡这两种机制。
事件捕获(Event Capturing)
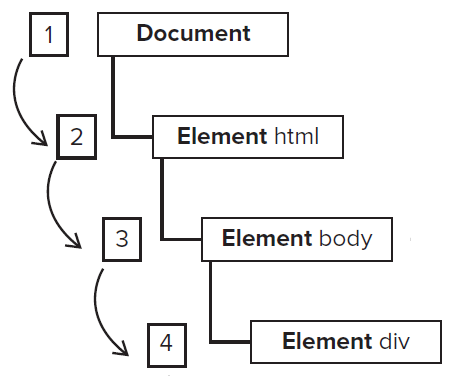
事件捕获指的是「从启动事件的元素节点开始,逐层往下传递」,直到最下层节点,也就是div。
事件冒泡(Event Bubbling)
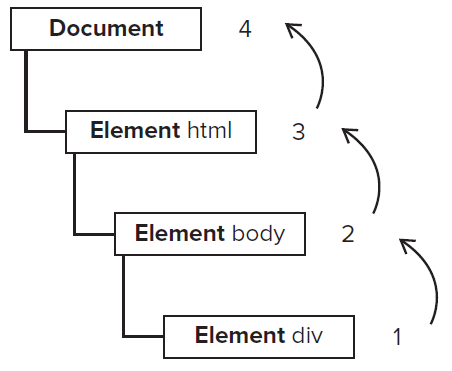
刚刚说过「事件捕获」机制是由上往下来传递,那么「事件冒泡」(Event Bubbling) 机制则正好相反。
既然事件传递顺序有这两种机制,那我怎么知道事件是依据哪种机制执行的呢?
答案是:两种都会执行。
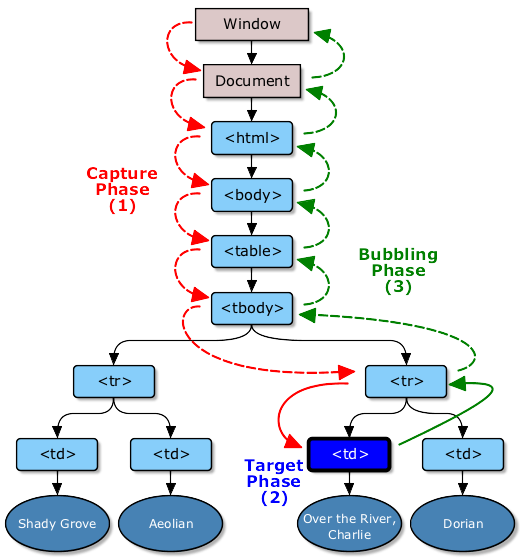
奇怪的知识
{} >= {} //true{} == {} //false{} <= {} //false[]+{} //"[object Object]" {}==0(浏览器解析的结果){}+[] // 0
setTimeOut(fn,0)多久才执行- 答:setTimeout 按照顺序放到队列里面,然后等待函数调用栈清空之后才开始执行,而这些操作进入队列的顺序,则由设定的延迟时间来决定
假值列表
- undefined
- null
- false
- +0, -0, NaN
- “”
this
四条规则
优先级: New绑定 > 显示绑定 > 隐性绑定 > 默认绑定
注意点:如果需要使用 bind 的柯里化和 apply 的数组解构,绑定到 null,尽可能使用 Object.create(null) 创建一个 DMZ 对象
- 默认绑定:没有其他显示绑定,在非严格模式下
this定义指向全局环境,在严格模式下this指向undefined
function foo() {
console.log(this.a);
}
var a = 2;
foo(); //2
- 隐性绑定: 调用位置是否有上下文对象,或者是否被某个对象拥有或者包含,那么隐式绑定规则会把函数调用中的
this绑定到这个上下文对象。而且,对象属性链只有上一层或者说最后一层在调用位置中起作用
function foo() {
console.log(this.a);
}
var obj = {
a: 2,
foo: foo,
}
obj.foo(); // 2
- 显示绑定(bind,call,apply):通过在函数上运行 call 和 apply ,来显示的绑定 this
function foo() {
console.log(this.a);
}
var obj = {
a: 2
};
foo.call(obj);
- 显示绑定之硬绑定(用bind去实现call和apply)
function foo(something) {
console.log(this.a, something);
return this.a + something;
}
function bind(fn, obj) {
return function() {
return fn.apply(obj, arguments);
};
}
var obj = {
a: 2
}
var bar = bind(foo, obj);
- New绑定:new 调用函数会创建一个全新的对象,并将这个对象绑定到函数调用的 this。
- 如果New绑定的是一个硬绑定函数,那么会用New新建的对象去替换这个硬绑定this
function foo(a) {
this.a = a;
}
var bar = new foo(2);
console.log(bar.a)//2
Promise 原理